
1. 分布式系统
1.1 集中式系统
集中式系统用一句话概括就是:一个主机带多个终端。终端没有数据处理能力,仅负责数据的录入和输出。而运算、存储等全部在主机上进行。
特点
集中式系统的最大的特点就是部署结构非常简单,底层一般采用从IBM、HP等厂商购买到的昂贵的大型主机。因此无需考虑如何对服务进行多节点的部署,也就不用考虑各节点之间的分布式协作问题。
但是,由于采用单机部署。很可能带来系统大而复杂、难于维护、发生单点故障(单个点发生故障的时候会波及到整个系统或者网络,从而导致整个系统或者网络的瘫痪)、扩展性差等问题。
正是由于集中式系统的问题在大量互联网中变得极为显著,因此诞生出分布式系统架构的使用必要性。
1.2 分布式系统(distributed system)
在《分布式系统概念与设计》一书中,对分布式系统做了如下定义:
分布式系统是一个硬件或软件组件分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调的系统。
简单来说就是一群独立计算机集合共同对外提供服务,但是对于系统的用户来说,就像是一台计算机在提供服务一样。
一个标准的分布式系统应该具有以下几个主要特征:
分布性
分布式系统中的多台计算机之间在空间位置上可以随意分布,系统中的多台计算机之间没有主、从之分,即没有控制整个系统的主机,也没有受控的从机。
透明性
系统资源被所有计算机共享。每台计算机的用户不仅可以使用本机的资源,还可以使用本分布式系统中其他计算机的资源(包括CPU、文件、打印机等)。
同一性
系统中的若干台计算机可以互相协作来完成一个共同的任务,或者说一个程序可以分布在几台计算机上并行地运行。
通信性
系统中任意两台计算机都可以通过通信来交换信息。
和集中式系统相比,分布式系统的性价比更高、处理能力更强、可靠性更高、也有很好的扩展性。
但是,分布式在解决了网站的高并发问题的同时也带来了一些其他问题:
首先,分布式的必要条件就是网络,这可能对性能甚至服务能力造成一定的影响。其次,一个集群中的服务器数量越多,服务器宕机的概率也就越大。
另外,由于服务在集群中分布式部署,用户的请求只会落到其中一台机器上,所以,一旦处理不好就很容易产生数据一致性问题。
2. 分布式系统关联的实际问题
说一下dubbo的工作原理?注册中心挂了可以继续通信吗?说说一次rpc请求的流程?
分布式系统的架构离不开分布式消息中间件、分布式搜索引擎、分布式缓存、RPC框架相关的问题:
原理性问题
kafka高可用架构原理、es分布式架构原理、redis线程模型原理、Dubbo工作原理。及这些技术的高级应用和特性。
新技术的新问题
每种技术引入之后生产环境都可能会碰到一些问题。
如何自己设计系统
如何自己设计MQ、如何自己设计搜索引擎,如何自己设计缓存,如何自己设计RPC框架
一般来说结合项目死扣细节是严格的面试官习惯的面试模式:
百度:深入底层、基础性;
阿里:结合项目死扣细节,扣很深的技术底层;
小米:数据结构和算法。
3. RPC(远程过程调用)
3.1 RPC
RPC,即 Remote Procedure Call(远程过程调用),是一个计算机通信协议。该协议允许运行于一台计算机的程序调用另一台计算机的子程序,而程序员无需额外地为这个交互作用编程。
通俗表述就是:A计算机提供一个服务,B计算机可以像调用本地服务那样调用A计算机的服务。
通过上面的概念可知,实现RPC主要是做到两点:
(1)实现远程调用其他计算机的服务
要实现远程调用,肯定是通过网络传输数据。A程序提供服务,B程序通过网络将请求参数传递给A,A本地执行后得到结果,再将结果返回给B程序。因此需要考虑:
- 采用何种网络通讯协议?
现在比较流行的RPC框架,都会采用TCP作为底层传输协议。
- 数据传输的格式怎样?
两个程序进行通讯,必须约定好数据传输格式。另外数据在网路中传输需要进行序列化,所以还需要约定统一的序列化的方式。
(2)像调用本地服务一样调用远程服务
如果仅仅是远程调用,还不算是RPC,因为RPC强调的是过程调用,调用的过程对用户而言是应该是透明的,用户不应该关心调用的细节,可以像调用本地服务一样调用远程服务。所以RPC一定要对调用的过程进行封装。
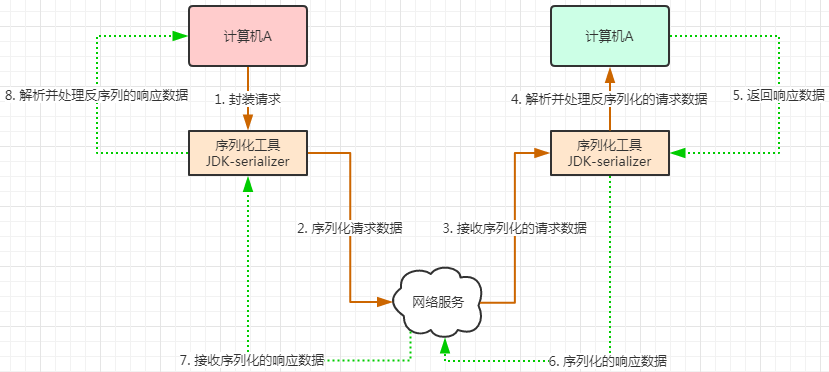
3.2 HTTP
Http协议,超文本传输协议,是一种应用层协议。规定了网络传输的请求格式、响应格式、资源定位和操作的方式等。但是底层采用什么网络传输协议,并没有规定,不过现在都是采用TCP协议作为底层传输协议。
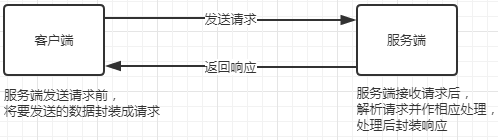
综上,Http与RPC的远程调用非常像,都是按照某种规定好的数据格式进行网络通信,有请求有响应。两者非常相似,但是还是有一些细微差别。
3.4 http 和 RPC 的区别
1)RPC并没有规定数据传输格式,这个格式可以任意指定,不同的RPC协议,数据格式不一定相同。
2)Http中还定义了资源定位的路径,RPC中并不需要
3)最重要的区别,RPC需要满足像调用本地服务一样调用远程服务,也就是对调用过程在API层面进行封装。Http协议没有这样的要求,因此请求、响应等细节需要我们自己去实现。
通过对比可以看出:
RPC方式更加透明,对用户更方便。Http方式更灵活,没有规定API和语言,跨语言、跨平台。但RPC方式需要在 API 层面进行封装,限制了开发的语言环境。
3.3 常见实现框架
3.3.1 国内框架
Dubbo
阿里开源的一款高性能RPC框架,在国内应用广泛,期间停止维护过一段时间,如今又开始了更新,并且捐献给Apache基金会,孵化中。
由于 spring cloud 全家桶的出现,也有很多公司转向 spring cloud 快速开发微服务。
Dubbox
当当团队基于Dubbo升级的一个版本,支持RESTful风格API的远程调用,基于Kryo/FST的Java高效序列化实现等功能,可直接用于生产环境。
Motan
新浪微博于2016年开源,”在微博平台中已经广泛应用,每天为数百个服务完成近千亿次的调用”。
3.3.2 国外框架
GRPC
Google开源,具有平台无关性,基于http/2协议,支持服务追踪、负载均衡、健康检查等功能。
Thrift
可伸缩的跨语言服务的RPC软件框架,最早由Facebook开发,2007年捐献给了Apache基金会管理,现在是Apache的顶级项目。
Finagle
Twitter基于Netty开发的支持容错的、协议无关的RPC框架,支撑了Twitter的核心服务。
4. Dubbo
4.1 框架设计
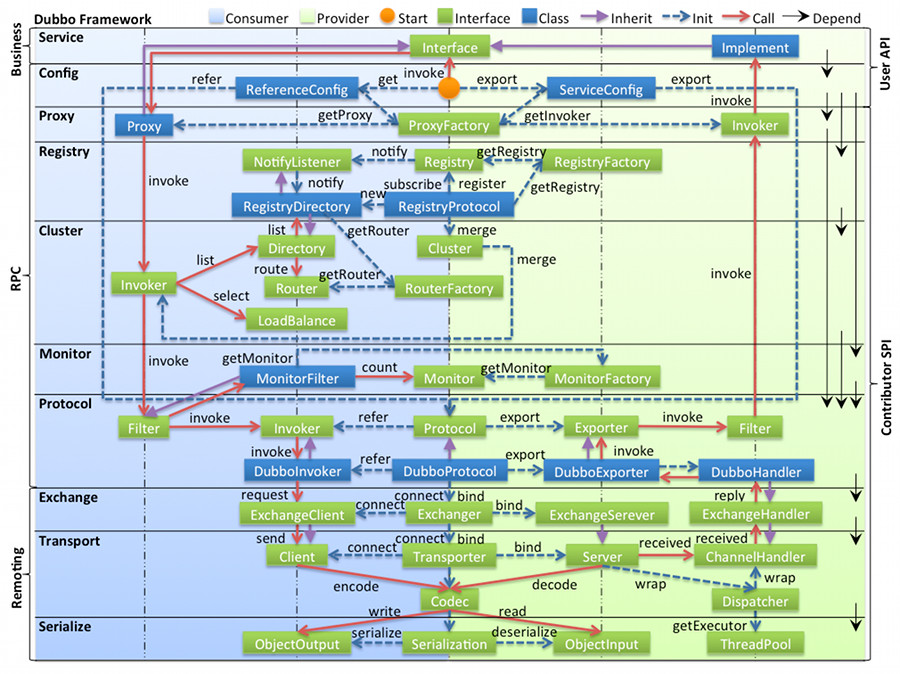
图例说明:
1)图中左边淡蓝背景的为服务消费方使用的接口,右边淡绿色背景的为服务提供方使用的接口,位于中轴线上的为双方都用到的接口。
2)图中从下至上分为十层,各层均为单向依赖,右边的黑色箭头代表层之间的依赖关系,每一层都可以剥离上层被复用,其中:Service 和 Config 层为 API,其它各层均为 SPI。
SPI 全称为 Service Provider Interface,是一种服务发现机制。SPI 的本质是将接口实现类的全限定名配置在文件中,并由服务加载器读取配置文件,加载实现类。这样可以在运行时,动态为接口替换实现类。
SPI 在
java.util.ServiceLoader的文档里有比较详细的介绍。不过,Dubbo 并未使用 Java 原生的 SPI 机制,而是对其进行了增强,使其能够更好的满足需求。如果想要学习 Dubbo 的源码,SPI 机制务必弄懂。
Dubbo SPI 官方文档:http://dubbo.apache.org/zh-cn/docs/source_code_guide/dubbo-spi.html
3)图中绿色小块的为扩展接口,蓝色小块为实现类,图中只显示用于关联各层的实现类。
4)图中蓝色虚线为初始化过程,即启动时组装链,红色实线为方法调用过程,即运行时调时链,紫色三角箭头为继承,可以把子类看作父类的同一个节点,线上的文字为调用的方法。
4.2 各层说明
service 配置层
接口层,其接口的具体实现是由服务提供者和消费者自己来实现。
config 配置层
对外配置接口,以 ServiceConfig, ReferenceConfig 为中心,可以直接初始化配置类,也可以通过 spring 解析配置生成配置类
proxy 服务代理层
服务接口透明代理,生成服务的客户端 Stub 和服务器端 Skeleton, 以 ServiceProxy为中心,扩展接口为 ProxyFactory
registry 注册中心层
封装服务地址的注册与发现,以服务 URL 为中心,扩展接口为 RegistryFactory, Registry, RegistryService
cluster 路由层
封装多个提供者的路由及负载均衡,并桥接注册中心,以 Invoker 为中心,扩展接口为 Cluster, Directory, Router, LoadBalance
monitor 监控层
RPC 调用次数和调用时间监控,以 Statistics 为中心,扩展接口为 MonitorFactory, Monitor, MonitorService
protocol 远程调用层
封装 RPC 调用,以 Invocation, Result 为中心,扩展接口为 Protocol, Invoker, Exporter
exchange 信息交换层
封装请求响应模式,同步转异步,以 Request, Response 为中心,扩展接口为 Exchanger, ExchangeChannel, ExchangeClient, ExchangeServer
transport 网络传输层
抽象 mina 和 netty 为统一接口,以 Message 为中心,扩展接口为 Channel, Transporter, Client, Server, Codec
serialize 数据序列化层
可复用的一些工具,扩展接口为 Serialization, ObjectInput, ObjectOutput, ThreadPool
官方参考文档:
4.3 工作流程
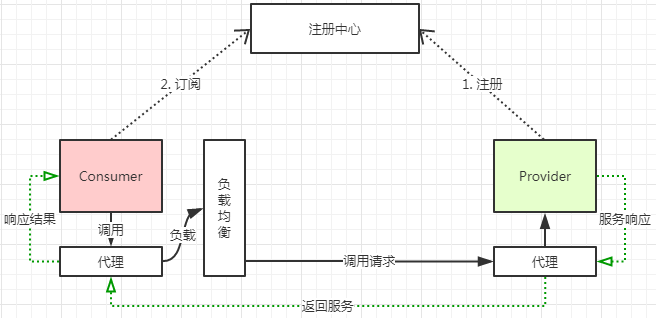
第一步,provider向注册中心注册。
第二步,consumer从注册中心订阅服务,注册中心会通知consumer注册成功的服务。
第三步,consumer调用provider提供接口。
第四步,consumer和provider都异步的通知监控中心。
官方参考文档:
服务调用过程:https://dubbo.apache.org/zh-cn/docs/source_code_guide/service-invoking-process.html
4.4 通信协议
dubbo支持哪些通信协议?支持哪些序列化协议?
4.4.1 dubbo://
Dubbo 缺省协议采用单一长连接和 NIO 异步通讯,适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况。
反之,Dubbo 缺省协议不适合传送大数据量的服务,比如传文件,传视频等,除非请求量很低。
4.4.2 hessian://
Hessian 协议用于集成 Hessian 的服务,Hessian 底层采用 Http 通讯,采用 Servlet 暴露服务,Dubbo 缺省内嵌 Jetty 作为服务器实现。
Hessian 是 Caucho 开源的一个 RPC 框架,其通讯效率高于 WebService 和 Java 自带的序列化。
Dubbo 的 Hessian 协议可以和原生 Hessian 服务互操作,即:
- 提供者用 Dubbo 的 Hessian 协议暴露服务,消费者直接用标准 Hessian 接口调用
- 或者提供方用标准 Hessian 暴露服务,消费方用 Dubbo 的 Hessian 协议调用。
官方参考文档:
协议参考手册:https://dubbo.apache.org/zh-cn/docs/user/references/protocol/introduction.html
性能测试报告:https://dubbo.apache.org/zh-cn/docs/user/perf-test.html
4.5 负载均衡
dubbo负载均衡策略和集群容错策略都有哪些?动态代理策略呢?
Dubbo 提供了 4 种负载均衡实现,分别是:
基于权重随机算法的RandomLoadBalance
基于最少活跃调用数算法的LeastActiveLoadBalance
基于 hash 一致性的ConsistentHashLoadBalance
基于加权轮询算法的RoundRobinLoadBalance
官方参考文档:
负载均衡源码分析:http://dubbo.apache.org/zh-cn/docs/source_code_guide/loadbalance.html
Dubbo的负载均衡:http://dubbo.apache.org/zh-cn/blog/dubbo-loadbalance.html
4.6 集群容错
4.6.1 集群容错策略
在集群调用失败时,Dubbo 提供了多种容错方案,缺省为 failover 重试。
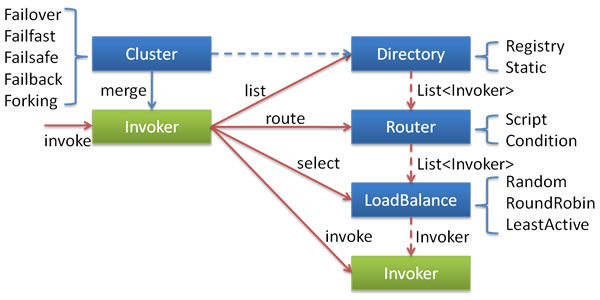
各节点关系:
- 这里的
Invoker是Provider的一个可调用Service的抽象,Invoker封装了Provider地址及Service接口信息 Directory代表多个Invoker,可以把它看成List<Invoker>,但与List不同的是,它的值可能是动态变化的,比如注册中心推送变更Cluster将Directory中的多个Invoker伪装成一个Invoker,对上层透明,伪装过程包含了容错逻辑,调用失败后,重试另一个Router负责从多个Invoker中按路由规则选出子集,比如读写分离,应用隔离等LoadBalance负责从多个Invoker中选出具体的一个用于本次调用,选的过程包含了负载均衡算法,调用失败后,需要重选
Dubbo主要内置了如下几种策略:
4.6.1.1 Failover Cluster
失败自动切换,当出现失败,重试其它服务器。Dubbo 默认的容错策略。
4.6.1.2 Failfast Cluster
快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
4.6.1.3 Failsafe Cluster
失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
4.6.1.4 Failback Cluster
失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
4.6.1.5 Forking Cluster
并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks="2" 来设置最大并行数。
4.6.1.6 Broadcast Cluster
广播调用所有提供者,逐个调用,任意一台报错则报错 [2]。通常用于通知所有提供者更新缓存或日志等本地资源信息。
官方参考文档:
Design For failure:https://dubbo.apache.org/zh-cn/blog/dubbo-cluster-error-handling.html
集群容错:http://dubbo.apache.org/zh-cn/docs/user/demos/fault-tolerent-strategy.html
4.6.2 各种策略对比
下表对各种策略做一个简单对比:
| 策略名称 | 优点 | 缺点 | 主要应用场景 |
|---|---|---|---|
| Failover | 对调用者屏蔽调用失败的信息 | 增加RT,额外资源开销,资源浪费 | 对调用rt不敏感的场景 |
| Failfast | 业务快速感知失败状态进行自主决策 | 产生较多报错的信息 | 非幂等性操作,需要快速感知失败的场景 |
| Failsafe | 即使失败了也不会影响核心流程 | 对于失败的信息不敏感,需要额外的监控 | 旁路系统,失败不影响核心流程正确性的场景 |
| Failback | 失败自动异步重试 | 重试任务可能堆积 | 对于实时性要求不高,且不需要返回值的一些异步操作 |
| Forking | 并行发起多个调用,降低失败概率 | 消耗额外的机器资源,需要确保操作幂等性 | 资源充足,且对于失败的容忍度较低,实时性要求高的场景 |
| Broadcast | 支持对所有的服务提供者进行操作 | 资源消耗很大 | 通知所有提供者更新缓存或日志等本地资源信息 |
4.7 动态代理扩展
dubbo 的 SPI 思想是什么?
官方参考文档:
Dubbo可扩展机制实战:http://dubbo.apache.org/zh-cn/blog/introduction-to-dubbo-spi.html
动态代理扩展:http://dubbo.apache.org/zh-cn/docs/dev/impls/proxy-factory.html
4.7.1 Java SPI 机制
Java SPI(Service Provider Interface)是JDK内置的一种动态加载扩展点的实现。在ClassPath的META-INF/services目录下放置一个与接口同名的文本文件,文件的内容为接口的实现类,多个实现类用换行符分隔。JDK中使用java.util.ServiceLoader来加载具体的实现。
4.7.2 Dubbo 的 SPI 机制
Java SPI的使用很简单。也做到了基本的加载扩展点的功能。但Java SPI有以下的不足:
- 需要遍历所有的实现,并实例化,然后我们在循环中才能找到我们需要的实现。
- 配置文件中只是简单的列出了所有的扩展实现,而没有给他们命名。导致在程序中很难去准确的引用它们。
- 扩展如果依赖其他的扩展,做不到自动注入和装配
- 不提供类似于Spring的IOC和AOP功能
- 扩展很难和其他的框架集成,比如扩展里面依赖了一个Spring bean,原生的Java SPI不支持
所以Java SPI应付一些简单的场景是可以的,但对于Dubbo,它的功能还是比较弱的。Dubbo对原生SPI机制进行了一些扩展。接下来,我们就更深入地了解下Dubbo的SPI机制。
4.7.3 Dubbo 的 SPI 的特点:
1)对Dubbo进行扩展,不需要改动Dubbo的源码
2)自定义的Dubbo的扩展点实现,是一个普通的Java类,Dubbo没有引入任何Dubbo特有的元素,对代码侵入性几乎为零。
3)将扩展注册到Dubbo中,只需要在ClassPath中添加配置文件。使用简单。而且不会对现有代码造成影响。符合开闭原则。
4)Dubbo的扩展机制设计默认值:@SPI(“dubbo”) 代表默认的spi对象
5)Dubbo的扩展机制支持IoC,AoP等高级功能
6)Dubbo的扩展机制能很好的支持第三方IoC容器,默认支持Spring Bean,可自己扩展来支持其他容器,比如Google的Guice。
7)切换扩展点的实现,只需要在配置文件中修改具体的实现,不需要改代码。使用方便。
4.7.4 如何扩展dubbo中的组件
首先自己实现org.apache.dubbo.rpc.Protocol接口,比如实现类叫:org.woodwhales.dubbo.MyProtocol,这个实现类可以是本地jar,也可以是pom.xml 依赖的远程jar。
随后将这个jar 信息配置到 dubbo 配置中:
1 | <!-- 声明协议,如果没有配置id,将以name为id --> |
最后,需要在META-INF配置文件中创建一个名称为:org.apache.dubbo.rpc.Protocol的配置文件,里面写上name对应的类全名:
如:
META-INF/dubbo/org.apache.dubbo.rpc.Protocol:
1 | myProtocol=org.woodwhales.dubbo.MyProtocol |
官方参考文档:http://dubbo.apache.org/zh-cn/docs/dev/impls/protocol.html
4.8 服务治理
如何基于dubbo进行服务治理、服务降级、失败重试以及超时重试?
服务治理是一个很复杂且很需要话费精力去研究的课题,一般会从以下方面进行课题研究:
1)调用链路自动生成
一个大型的分布式系统或微服务架构,其系统是由大量的服务组成。那么这些服务之间互相是如何调用的?调用链路是怎么样的?就需要基于dubbo做的分布式系统中,对各个服务之间的调用自动记录下来,然后自动将各个服务之间的依赖关系和调用链路生成出来,做成一张可视化的图,方便查看当前服务的运行情况。
dubbo 服务治理官方参考文档:
服务治理和配置管理:http://dubbo.apache.org/zh-cn/docs/admin/serviceGovernance.html
2)服务访问压力以及时长统计
需要自动统计各个接口和服务之间的调用次数以及访问延时,而且要分成两个级别。
一个级别是接口粒度,就是每个服务的每个接口每天被调用多少次,TP50,TP90,TP99,三个档次的请求延时分别是多少;
第二个级别是从源头入口开始,一个完整的请求链路经过几十个服务之后,完成一次请求,每天全链路走多少次,全链路请求延时的TP50,TP90,TP99,分别是多少。
这些东西都搞定了之后,后面才可以来看当前系统的压力主要在哪里,如何来扩容和优化。
3)其他
服务分层(避免循环依赖),调用链路失败监控和报警,服务鉴权,每个服务的可用性的监控(接口调用成功率?几个9?)99.99%,99.9%,99%。
4.9 服务降级
比如服务A调用服务B,结果服务B挂掉了,暂停了服务,此时服务A会重试多次尝试继续调用服务B,发现一直无法正常调用,那么就需要将服务A采取降级措施:让服务A执行一个备用的逻辑,给用户返回响应。
Dubbo 中可以在消费者的配置一个本地伪装的mock服务。
官方参考文档:
本地伪装:http://dubbo.apache.org/zh-cn/docs/user/demos/local-mock.html
服务降级:http://dubbo.apache.org/zh-cn/docs/user/demos/service-downgrade.html
4.10 失败/超时重试
Dubbo启动时默认有重试机制和超时机制。 超时机制的规则是如果在一定的时间内,provider没有返回,则认为本次调用失败, 重试机制在出现调用失败时,会再次调用。如果在配置的调用次数内都失败,则认为此次请求异常,抛出异常。
重试机制带来的问题
由于服务响应慢,Dubbo自身的超时重试机制可能会带来一些麻烦,常见的应用场景故障:重复发送邮件 、重复账户注册。
解决方案
1)对于核心的服务中心,去除dubbo超时重试机制,并重新评估设置超时时间。
去掉超时重试机制 :
1 | <dubbo:provider delay="-1" timeout="6000" retries="0"/> |
重新评估设置超时时间:
1 | <dubbo:service interface="*.*" ref="*" timeout="延长服务时间"/> |
2)业务处理代码必须放在服务端,客户端只做参数验证和服务调用,不涉及业务流程处理。
5. 幂等性
分布式服务接口的幂等性如何设计(比如不能重复扣款)?
幂等性问题不是技术问题,这个问题没有通用方法,需要结合业务来看应该如何保证幂等性。
基于唯一标识,存到缓存中或者存到数据库中,因此每次操作就有了一个操作日志。当第一个操作请求操作了就记录下来,下一个相同的操作发现有这个操作的日志,那么就不再执行这次操作。
6. 顺序性
对于数据顺性不严格的情况下,可以使用算法将同一个操作的相同操行都 hash 到同一个节点中,节点机器系统的内部使用内存队列来顺序执行操作,这样能很大程度保证数据的顺序性。
如果对数据的顺序性十分严格,那么就需要使用到分布式锁 + 消息中间件,但是这样会使得高并发的性能降低。
7.如何自己设计一个RPC框架
7.1 实现思路
- RPC有两个使用方式:一个是本地调用端,一个是远程实现端
- 调用端使用动态代理,代理消费者需要远程调用的接口。
- 将本地调用的接口方法信息(形参,方法名,返回类型等)通过网络发送至远程实现端。
- 远程实现端接收到相应信息,反射调用对象的实现类。
- 执行完实现类后把返回值发回给调用端。
- 调用端接收到返回值,代理返回结果,远程调用完毕。
7.2 实现细节问题
远程调用要解决的主要/细节问题:
1)序列化 : 如何将对象转化为二进制数据进行传输,如何将二进制数据转化对象。
可以使用java自带的序列化,Hessian,protobuff,json,xml等
性能比较高的是protobuff和hessian,protobuff使用的时候需要编写proto文件,有侵入性,比较麻烦,而Hessian性能比protobuff稍差,不过近来出现了一个基于protobuff的框架:protostuff--不用编写proto文件,基于注解,性能可以,推荐使用。
2)数据的传输(协议,第三方框架,如netty)
出于并发性能的考虑,传统的阻塞式 IO 显然不太合适,因此我们需要异步的 IO,即 NIO。Java 提供了 NIO 的解决方案,Java 7 也提供了更优秀的NIO.2支持。可以选择Netty或者mina来解决 NIO 数据传输的问题。
3)服务的注册/发现,单点故障,分布式服务
使用ZooKeeper提供服务注册与发现功能,解决单点故障以及分布式部署的问题(注册中心)
4)服务的监控和管理
需要单独开发一个应用对服务进行监控和管理。
8. 扩展资料
HTTP,TCP, socket,RPC 与gRPC都是啥?
dubbo 序列化机制之 hessian2序列化实现原理分析
Dubbo扩展点加载机制 - ExtensionLoader
HTTP幂等性概念和应用 | 酷 壳 – CoolShell
基于redis(lua)和zookeeper分布式锁(秒杀)实现,分布式接口幂等实现,分布式速率限制实现,分布式ID生成器实现
深入浅出Zookeeper(二) 基于Zookeeper的分布式锁与领导选举
【远程调用框架】如何实现一个简单的RPC框架(一)想法与设计
从 0 到 1 编写一个 RPC 框架 (基于 Zookeeper)
高并发架构系列:如何从0到1设计一个类Dubbo的RPC框架
RPCX: 一个用Go实现的类似Dubbo的分布式RPC框架
API设计,从RPC、SOAP、REST到GraphQL(一)
Java打造RPC框架(二):11个类实现简单Java RPC
视频/专栏学习资料:
深入理解 RPC : 基于 Python 自建分布式高并发 RPC 服务
2019Java微服务架构(SpringBoot+Dubbo+Zookeeper)
老司机带你在分布式系统下掌握编程式事务以及接口的幂等性设计精髓
参考书籍:
《大型网站系统与Java中间件实践》